SEO checklist for ReactiveSearch

High-performing Frontend Engineer with 5+ years of experience driving innovation in startups and open-source communities. Proven expertise in:
- Co-authoring/contributing to libraries like reactivesearch, searchbox, and appbase-js
- Building search experiences with robust features like analytics, machine learning, and pipelines
- Developing a no-code/low-code UI builder for rapid search experience creation
Key Achievements:
- Slashed search interface development time by 90% (from months to hours)
- Enabled rapid multi-page creation in under 5 minutes with customizable templates and built-in authentication
- Supported React and Vue, increasing time-to-market by 100-200% and reducing maintenance costs
Active community member, sharing knowledge through blogs on Hashnode. Versatile professional with experience in:
- Dev relations and interview conducting
- Mentoring and collaborating with teams (mentored over 3 batches of candidates)
- Remote work with a self-driven attitude (working remotely since the start of my career)
Passionate about airplanes, yoga, and swimming. Let's connect and build something amazing!
For your website to appear in a search engine’s results, the search engine needs to be able to discover, crawl, parse, and render the key pages of your site.
When building your search experience with client-side JavaScript, you may worry that search engines can’t crawl or render your URLs and that this may hurt your ranking. While some search engines are getting better at processing sites with client-side JavaScript search, you can also do a lot to optimize your website for search engines without sacrificing the user experience.
Your search result pages are directly accessible through a URL
As users interact with your search interface, the URL should dynamically update and reflect the refinements they’ve selected and their actions.
This allows them to share links to your website, enhancing the overall usability of your search and encouraging backlinking.
Try opening the code sandbox in a new tab and see how the URLs are changing with every significant search interaction.
The approach clearly improves the user experience, but there are concerns or well-spread myths about dynamic URLs that require busting.
#1 Myth: "Dynamic URLs cannot be crawled."
#2 Myth: "Dynamic URLs are okay if you use fewer than three parameters."
Having read the above references we can safely conclude that Dynamic URLs don't necessarily hurt your SEO and should be favored.
Your widgets use crawlable a tags with href attributes
Search Engines can follow your links only if they use proper <a> tags with resolvable URLs.
✅ Dos:
<a href="https://example.com"><a href="/relative/path/file">
Note that links are also crawlable when you use JavaScript to insert them into a page dynamically as long as it uses the markup shown above.
don'ts:
<a routerLink="some/path"><span href="https://example.com"><a onclick="goto('https://example.com')">
This is relevant when you have opted to use custom markup.
Your URLs are readable
A site's URL structure should be as simple as possible. Consider organizing your content so that URLs are constructed logically and in a manner that is most intelligible to humans.

For every ReactiveSearch component/ widget, the basic routing configuration injects every search refinement into the URL as a query string parameter. These parameters are inferred from the global search state.
https://fwmwo.csb.app/?BookName=Paradise
// The below information is saved legibly in the URL params above
// componentId = 'BookName'
// component's value = 'Paradise'
// you can visit the above mentioned app to see how the URls are handled out of the box
✅ Dos
Simple, descriptive words in the URL
https://en.wikipedia.org/wiki/AviationLocalized words in the URL, if applicable.
https://www.example.com/lebensmittel/pfefferminzUse UTF-8 encoding as necessary. For example, the following example uses UTF-8 encoding for Arabic characters in the URL:
https://www.example.com/%D9%86%D8%B9%D9%86%D8%A7%D8%B9/%D8%A8%D9%82%D8%A7%D9%84%D8%A9
🚫 Don'ts
Using non-ASCII characters in the URL:
https://www.example.com/نعناع,https://www.example.com/杂货/薄荷, etc.Unreadable, long ID numbers in the URL:
https://www.example.com/index.php?id_sezione=360&sid=3a5ebc944f41daa6f849f730f1
Although ReactiveSearch by default uses query strings for the Search UIs, but also provides support for customization to switch to path based routing.
ReactiveBase supports two props to allow users to control how the URL of the search UI behaves.
- getSearchParams
| Type | Optional |
Function | Yes |
Enables you to customize the evaluation of query-params-string from the URL (or) any other source. If this function is not set, the library will use window.location.search as the search query-params-string for parsing selected values. This can come in handy if the URL is using hash values.
- setSearchParams
| Type | Optional |
Function | Yes |
Enables you to customize the setting of the query params string in the URL by providing the updated query-params-string as the function parameter. If this function is not set, the library will set the window.history via pushState method.
In our example attached below,
We leverage setSearchParams to receive a URL decorated with query params and manipulate the query params to generate a human-friendly route, finally applying it using window.history.pushState method.
setSearchParams = (urlWithQueryParams) => {
// build URL with category and sub-category path
window.history.pushState({ path: urlWithPath }, '', urlWithPath);
}
On the other hand getSearchParams callback is used to parse the path-based URL and turn it into library supported URL with query params.
getSearchParams = () => {
// extract query params from the path
// path $host/Best%20%Buy/Mobile?color=red&page=2
// Extract query params: category=Best%2-Buy&sub-category=Mobile&color=red&page=2
return newURLwithAllParams
}
Voila 🎊 Try selecting the category and the subcategory in the example to see the route's path changing.
Resources
Your URLs reflect the structure of your website
Some search engines use your URL structure to infer the architecture of your website, understand the context of a page, and enhance its relevance to a particular search query.
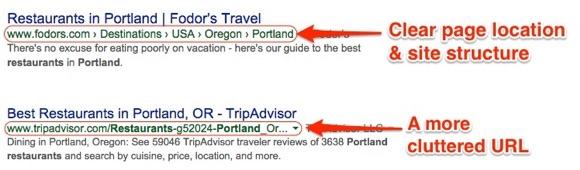
Well-structured URLs offer users a quick hint about the page topic and how the page fits within the website.
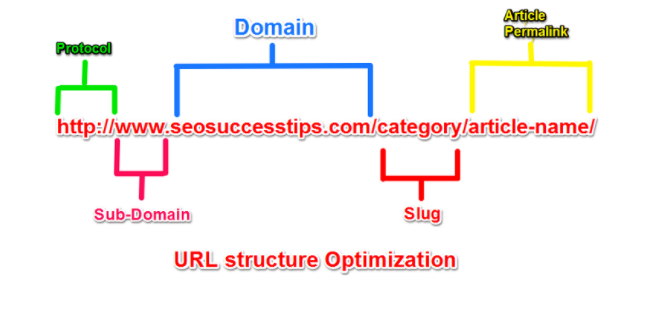
For example, if a website has categories and sub-categories, each category should be reachable through https://mywebsite.com/<category>/ and each sub-category through https://mywebsite.com/<category>/<sub-category>.
✅ Dos
🚫 Don'ts
Resources -
Your site is using a pre-rendering technique
The first question is, "Why do we even need to pre-render an HTML page"?
In the CSR technique, which has come into our lives with modern browsers, websites send very little HTML response to connection requests. This HTML response contains JavaScript codes that make up the content of the page. Unless these JavaScript codes are executed, the website is a blank page. The browser renders these JavaScript files, creates the content, and presents the web page to us.
🚫✋🏻 But wait ✋🏻🚫, The server sends little to no HTML but a script to be executed on the client side which in turn is responsible for generating the HTML. The crawlers have got a problem with this. The crawlers primarily like HTML and don't wait to execute JS to parse the content of the page.

Not all search engine crawlers can process JavaScript successfully or immediately. Fortunately, there are many ways around it.
Server-side rendering (SSR)
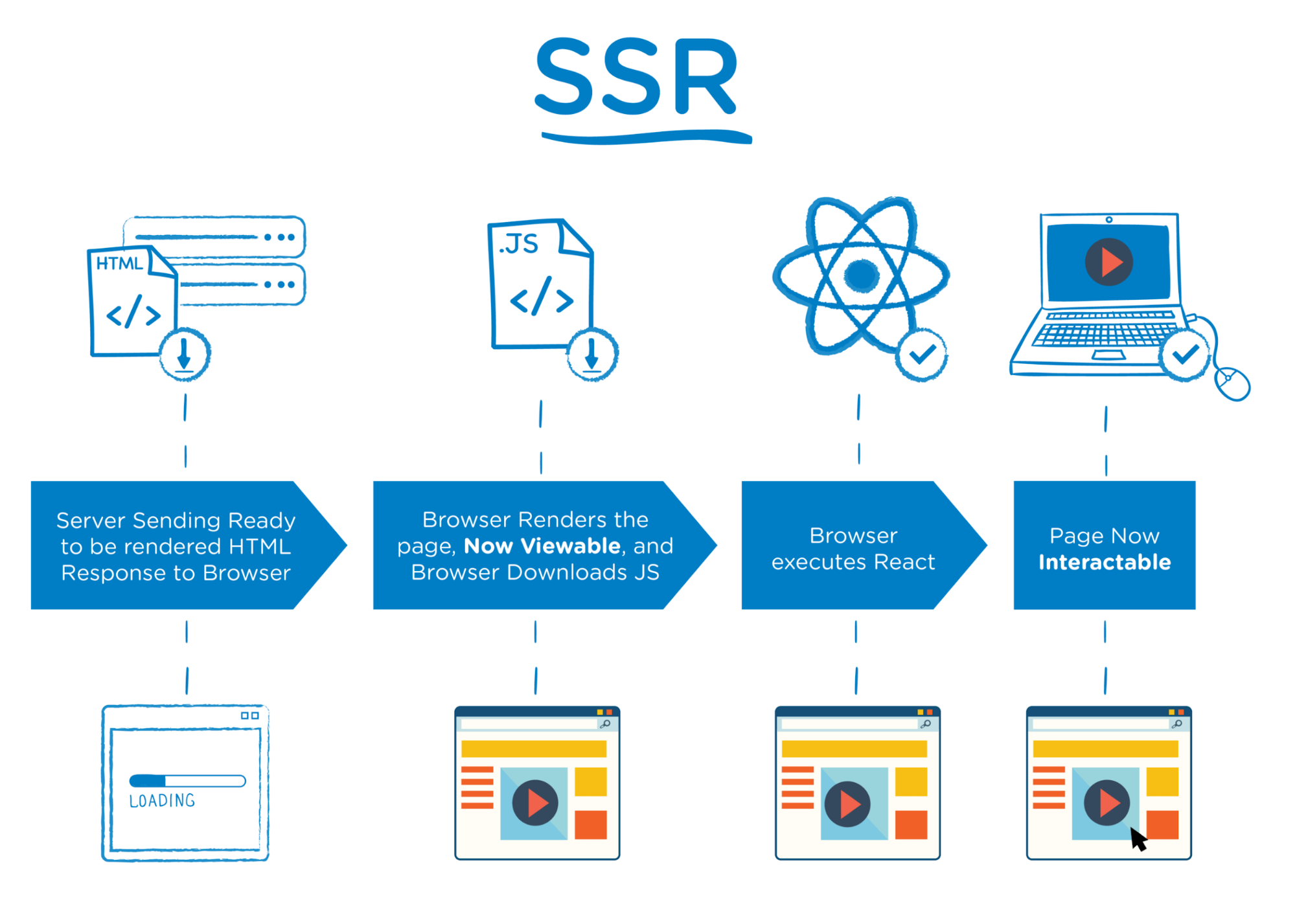
This technique fetches your data and renders a JavaScript website on the server before sending it to the browser. This process is commonly implemented through modern frameworks such as React, Angular, and Vue.
Let's help you out 🤝
Reactivesearch internally runs on a redux store. With Server Side Rendering, you can handle the initial render when a user (or search engine crawler) first requests your app. To achieve the relevant results on an initial render, we need to pre-populate the redux store of ReactiveSearch.
Visit our docs here to know more.
A quick demo -
Resources